








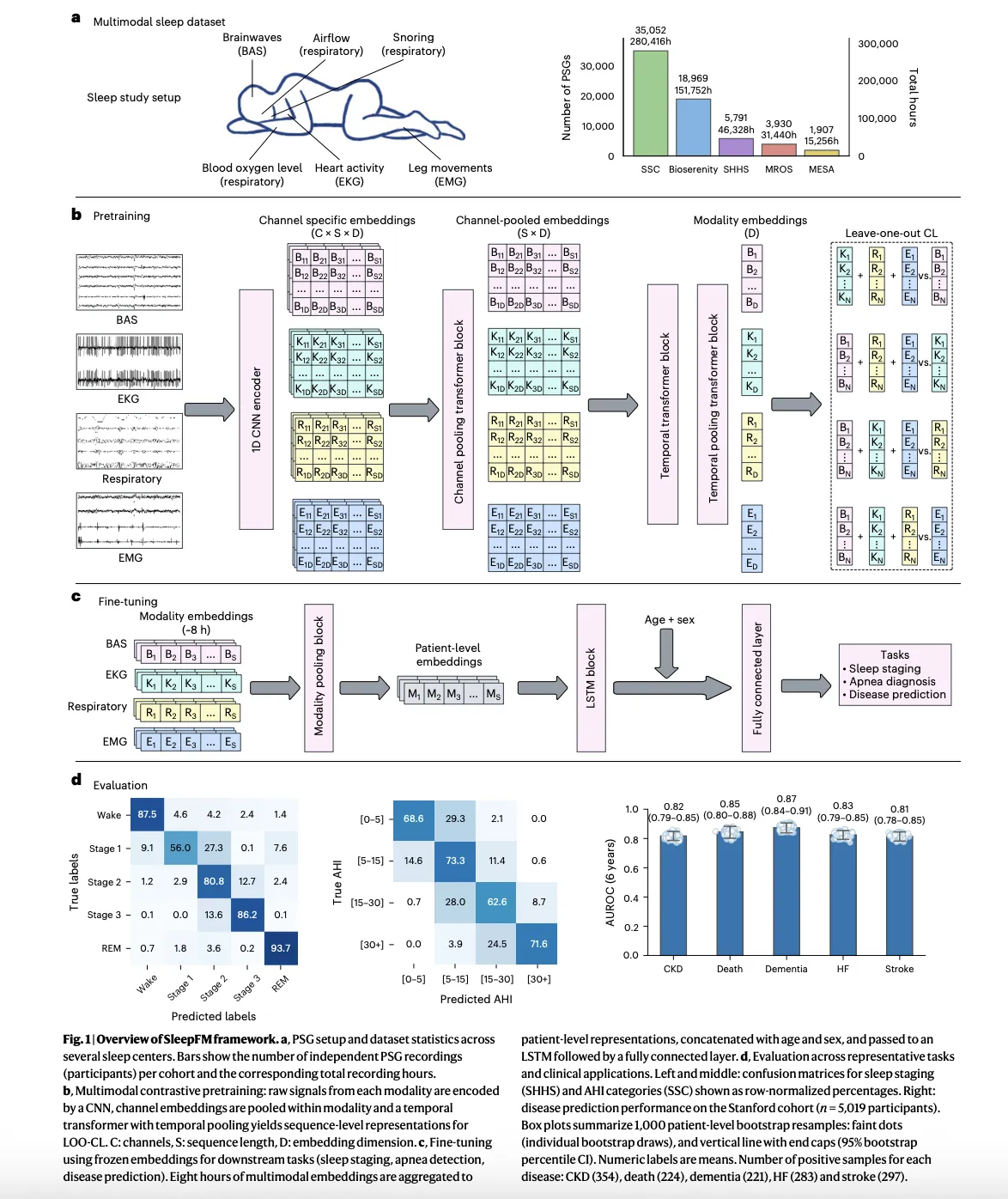











A Coding Guide to Demonstrate Targeted Data Poisoning Attacks in Deep Learning by Label Flipping on CIFAR-10 with PyTorch

In this tutorial, we demonstrate a realistic data poisoning attack by manipulating labels in the CIFAR-10 dataset and observing its impact on model behavior. We construct a clean and a poisoned training pipeline side by side, using a ResNet-style convolutional network to ensure stable, comparable learning dynamics. By selectively flipping a fraction of samples from a target class to a malicious class during training, we show how subtle corruption in the data pipeline can propagate into systematic misclassification at inference time. Check out the FULL CODES here.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, classification_report
CONFIG = {
"batch_size": 128,
"epochs": 10,
"lr": 0.001,
"target_class": 1,
"malicious_label": 9,
"poison_ratio": 0.4,
}
torch.manual_seed(42)
np.random.seed(42)We set up the core environment required for the experiment and define all global configuration parameters in a single place. We ensure reproducibility by fixing random seeds across PyTorch and NumPy. We also explicitly select the compute device so the tutorial runs efficiently on both CPU and GPU. Check out the FULL CODES here.
class PoisonedCIFAR10(Dataset):
def __init__(self, original_dataset, target_class, malicious_label, ratio, is_train=True):
self.dataset = original_dataset
self.targets = np.array(original_dataset.targets)
self.is_train = is_train
if is_train and ratio > 0:
indices = np.where(self.targets == target_class)[0]
n_poison = int(len(indices) * ratio)
poison_indices = np.random.choice(indices, n_poison, replace=False)
self.targets[poison_indices] = malicious_label
def __getitem__(self, index):
img, _ = self.dataset[index]
return img, self.targets[index]
def __len__(self):
return len(self.dataset)We implement a custom dataset wrapper that enables controlled label poisoning during training. We selectively flip a configurable fraction of samples from the target class to a malicious class while keeping the test data untouched. We preserve the original image data so that only label integrity is compromised. Check out the FULL CODES here.
def get_model():
model = torchvision.models.resnet18(num_classes=10)
model.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
model.maxpool = nn.Identity()
return model.to(CONFIG["device"])
def train_and_evaluate(train_loader, description):
model = get_model()
optimizer = optim.Adam(model.parameters(), lr=CONFIG["lr"])
criterion = nn.CrossEntropyLoss()
for _ in range(CONFIG["epochs"]):
model.train()
for images, labels in train_loader:
images = images.to(CONFIG["device"])
labels = labels.to(CONFIG["device"])
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
return modelWe define a lightweight ResNet-based model tailored for CIFAR-10 and implement the full training loop. We train the network using standard cross-entropy loss and Adam optimization to ensure stable convergence. We keep the training logic identical for clean and poisoned data to isolate the effect of data poisoning. Check out the FULL CODES here.
def get_predictions(model, loader):
model.eval()
preds, labels_all = [], []
with torch.no_grad():
for images, labels in loader:
images = images.to(CONFIG["device"])
outputs = model(images)
_, predicted = torch.max(outputs, 1)
preds.extend(predicted.cpu().numpy())
labels_all.extend(labels.numpy())
return np.array(preds), np.array(labels_all)
def plot_results(clean_preds, clean_labels, poisoned_preds, poisoned_labels, classes):
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
for i, (preds, labels, title) in enumerate([
(clean_preds, clean_labels, "Clean Model Confusion Matrix"),
(poisoned_preds, poisoned_labels, "Poisoned Model Confusion Matrix")
]):
cm = confusion_matrix(labels, preds)
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", ax=ax[i],
xticklabels=classes, yticklabels=classes)
ax[i].set_title(title)
plt.tight_layout()
plt.show()We run inference on the test set and collect predictions for quantitative analysis. We compute confusion matrices to visualize class-wise behavior for both clean and poisoned models. We use these visual diagnostics to highlight targeted misclassification patterns introduced by the attack. Check out the FULL CODES here.
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010))
])
base_train = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform=transform)
base_test = torchvision.datasets.CIFAR10(root="./data", train=False, download=True, transform=transform)
clean_ds = PoisonedCIFAR10(base_train, CONFIG["target_class"], CONFIG["malicious_label"], ratio=0)
poison_ds = PoisonedCIFAR10(base_train, CONFIG["target_class"], CONFIG["malicious_label"], ratio=CONFIG["poison_ratio"])
clean_loader = DataLoader(clean_ds, batch_size=CONFIG["batch_size"], shuffle=True)
poison_loader = DataLoader(poison_ds, batch_size=CONFIG["batch_size"], shuffle=True)
test_loader = DataLoader(base_test, batch_size=CONFIG["batch_size"], shuffle=False)
clean_model = train_and_evaluate(clean_loader, "Clean Training")
poisoned_model = train_and_evaluate(poison_loader, "Poisoned Training")
c_preds, c_true = get_predictions(clean_model, test_loader)
p_preds, p_true = get_predictions(poisoned_model, test_loader)
plot_results(c_preds, c_true, p_preds, p_true, classes)
print(classification_report(c_true, c_preds, target_names=classes, labels=[1]))
print(classification_report(p_true, p_preds, target_names=classes, labels=[1]))We prepare the CIFAR-10 dataset, construct clean and poisoned dataloaders, and execute both training pipelines end to end. We evaluate the trained models on a shared test set to ensure a fair comparison. We finalize the analysis by reporting class-specific precision and recall to expose the impact of poisoning on the targeted class.
In conclusion, we observed how label-level data poisoning degrades class-specific performance without necessarily destroying overall accuracy. We analyzed this behavior using confusion matrices and per-class classification reports, which reveal targeted failure modes introduced by the attack. This experiment reinforces the importance of data provenance, validation, and monitoring in real-world machine learning systems, especially in safety-critical domains.
Check out the FULL CODES here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Check out our latest release of ai2025.dev, a 2025-focused analytics platform that turns model launches, benchmarks, and ecosystem activity into a structured dataset you can filter, compare, and export.
The post A Coding Guide to Demonstrate Targeted Data Poisoning Attacks in Deep Learning by Label Flipping on CIFAR-10 with PyTorch appeared first on MarkTechPost.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0