








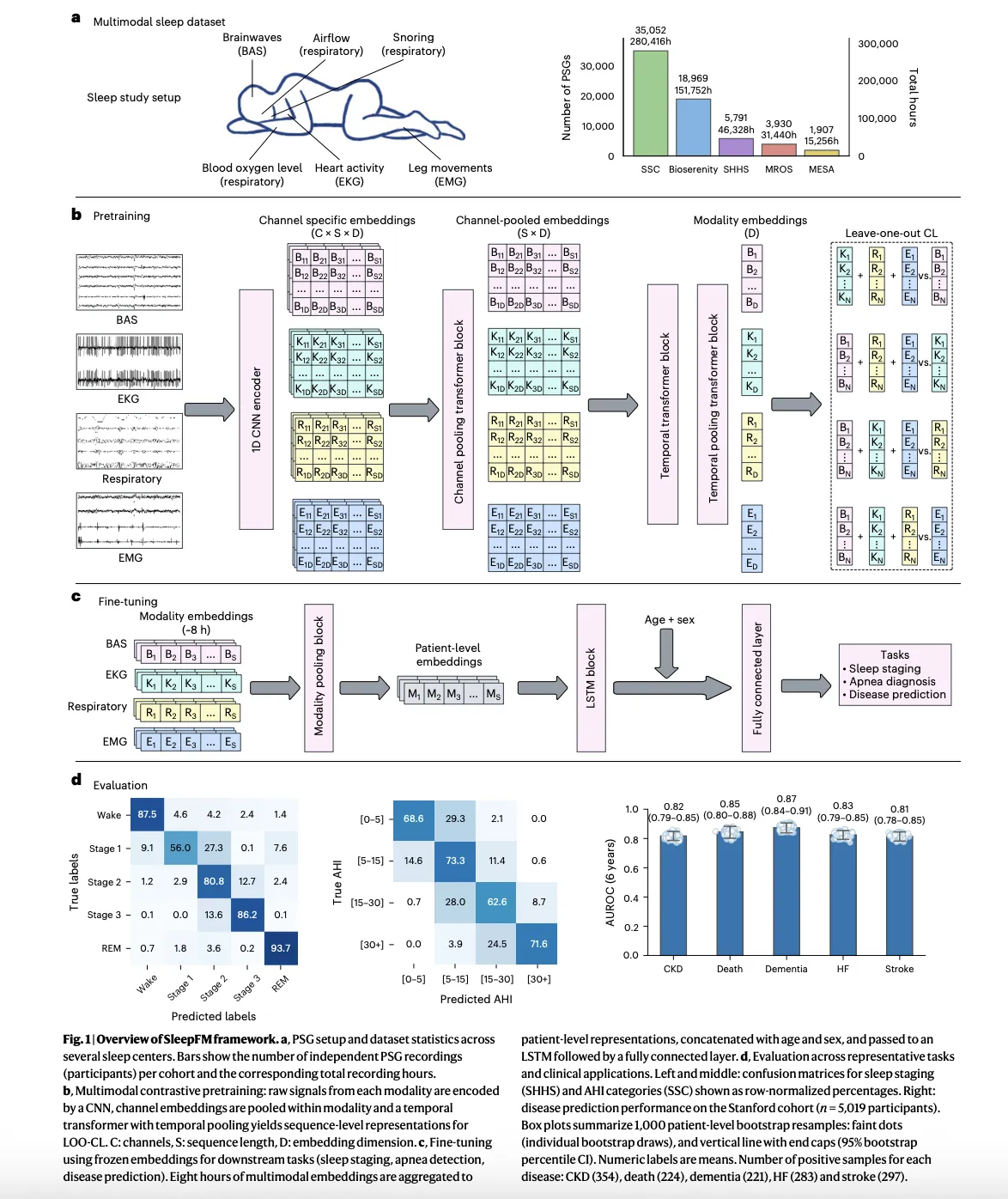











How to Build Portable, In-Database Feature Engineering Pipelines with Ibis Using Lazy Python APIs and DuckDB Execution

In this tutorial, we demonstrate how we use Ibis to build a portable, in-database feature engineering pipeline that looks and feels like Pandas but executes entirely inside the database. We show how we connect to DuckDB, register data safely inside the backend, and define complex transformations using window functions and aggregations without ever pulling raw data into local memory. By keeping all transformations lazy and backend-agnostic, we demonstrate how to write analytics code once in Python and rely on Ibis to translate it into efficient SQL. Check out the FULL CODES here.
!pip -q install "ibis-framework[duckdb,examples]" duckdb pyarrow pandas
import ibis
from ibis import _
print("Ibis version:", ibis.__version__)
con = ibis.duckdb.connect()
ibis.options.interactive = TrueWe install the required libraries and initialize the Ibis environment. We establish a DuckDB connection and enable interactive execution so that all subsequent operations remain lazy and backend-driven. Check out the FULL CODES here.
try:
base_expr = ibis.examples.penguins.fetch(backend=con)
except TypeError:
base_expr = ibis.examples.penguins.fetch()
if "penguins" not in con.list_tables():
try:
con.create_table("penguins", base_expr, overwrite=True)
except Exception:
con.create_table("penguins", base_expr.execute(), overwrite=True)
t = con.table("penguins")
print(t.schema())We load the Penguins dataset and explicitly register it inside the DuckDB catalog to ensure it is available for SQL execution. We verify the table schema and confirm that the data now lives inside the database rather than in local memory. Check out the FULL CODES here.
def penguin_feature_pipeline(penguins):
base = penguins.mutate(
bill_ratio=_.bill_length_mm / _.bill_depth_mm,
is_male=(_.sex == "male").ifelse(1, 0),
)
cleaned = base.filter(
_.bill_length_mm.notnull()
& _.bill_depth_mm.notnull()
& _.body_mass_g.notnull()
& _.flipper_length_mm.notnull()
& _.species.notnull()
& _.island.notnull()
& _.year.notnull()
)
w_species = ibis.window(group_by=[cleaned.species])
w_island_year = ibis.window(
group_by=[cleaned.island],
order_by=[cleaned.year],
preceding=2,
following=0,
)
feat = cleaned.mutate(
species_avg_mass=cleaned.body_mass_g.mean().over(w_species),
species_std_mass=cleaned.body_mass_g.std().over(w_species),
mass_z=(
cleaned.body_mass_g
- cleaned.body_mass_g.mean().over(w_species)
) / cleaned.body_mass_g.std().over(w_species),
island_mass_rank=cleaned.body_mass_g.rank().over(
ibis.window(group_by=[cleaned.island])
),
rolling_3yr_island_avg_mass=cleaned.body_mass_g.mean().over(
w_island_year
),
)
return feat.group_by(["species", "island", "year"]).agg(
n=feat.count(),
avg_mass=feat.body_mass_g.mean(),
avg_flipper=feat.flipper_length_mm.mean(),
avg_bill_ratio=feat.bill_ratio.mean(),
avg_mass_z=feat.mass_z.mean(),
avg_rolling_3yr_mass=feat.rolling_3yr_island_avg_mass.mean(),
pct_male=feat.is_male.mean(),
).order_by(["species", "island", "year"])We define a reusable feature engineering pipeline using pure Ibis expressions. We compute derived features, apply data cleaning, and use window functions and grouped aggregations to build advanced, database-native features while keeping the entire pipeline lazy. Check out the FULL CODES here.
features = penguin_feature_pipeline(t)
print(con.compile(features))
try:
df = features.to_pandas()
except Exception:
df = features.execute()
display(df.head())We invoke the feature pipeline and compile it into DuckDB SQL to validate that all transformations are pushed down to the database. We then run the pipeline and return only the final aggregated results for inspection. Check out the FULL CODES here.
con.create_table("penguin_features", features, overwrite=True)
feat_tbl = con.table("penguin_features")
try:
preview = feat_tbl.limit(10).to_pandas()
except Exception:
preview = feat_tbl.limit(10).execute()
display(preview)
out_path = "/content/penguin_features.parquet"
con.raw_sql(f"COPY penguin_features TO '{out_path}' (FORMAT PARQUET);")
print(out_path)We materialize the engineered features as a table directly inside DuckDB and query it lazily for verification. We also export the results to a Parquet file, demonstrating how we can hand off database-computed features to downstream analytics or machine learning workflows.
In conclusion, we constructed, compiled, and executed an advanced feature engineering workflow fully inside DuckDB using Ibis. We demonstrated how to inspect the generated SQL, materialized results directly in the database, and exported them for downstream use while preserving portability across analytical backends. This approach reinforces the core idea behind Ibis: we keep computation close to the data, minimize unnecessary data movement, and maintain a single, reusable Python codebase that scales from local experimentation to production databases.
Check out the FULL CODES here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Check out our latest release of ai2025.dev, a 2025-focused analytics platform that turns model launches, benchmarks, and ecosystem activity into a structured dataset you can filter, compare, and export.
The post How to Build Portable, In-Database Feature Engineering Pipelines with Ibis Using Lazy Python APIs and DuckDB Execution appeared first on MarkTechPost.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0